
Using lakeFS with Apache Spark
There are several ways to use lakeFS with Spark:
- The S3-compatible API: Scalable and best to get started. All Storage Vendors
- The lakeFS FileSystem: Direct data flow from client to storage, highly scalable. AWS S3
- lakeFS FileSystem in Presigned mode: Best of both worlds. AWS S3Azure Blob
See how SimilarWeb is using lakeFS with Spark to manage algorithm changes in data pipelines.
S3-compatible API
lakeFS has an S3-compatible endpoint which you can point Spark at to get started quickly.
You will access your data using S3-style URIs, e.g. s3a://example-repo/example-branch/example-table.
You can use the S3-compatible API regardless of where your data is hosted.
Configuration
To configure Spark to work with lakeFS, we set S3A Hadoop configuration to the lakeFS endpoint and credentials:
fs.s3a.access.key: lakeFS access keyfs.s3a.secret.key: lakeFS secret keyfs.s3a.endpoint: lakeFS S3-compatible API endpoint (e.g. https://example-org.us-east-1.lakefscloud.io)fs.s3a.path.style.access:true
Here is how to do it:
spark-shell --conf spark.hadoop.fs.s3a.access.key='AKIAlakefs12345EXAMPLE' \
--conf spark.hadoop.fs.s3a.secret.key='abc/lakefs/1234567bPxRfiCYEXAMPLEKEY' \
--conf spark.hadoop.fs.s3a.path.style.access=true \
--conf spark.hadoop.fs.s3a.endpoint='https://example-org.us-east-1.lakefscloud.io' ...
spark.sparkContext.hadoopConfiguration.set("fs.s3a.access.key", "AKIAlakefs12345EXAMPLE")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.secret.key", "abc/lakefs/1234567bPxRfiCYEXAMPLEKEY")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.endpoint", "https://example-org.us-east-1.lakefscloud.io")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.path.style.access", "true")
Add these into a configuration file, e.g. $SPARK_HOME/conf/hdfs-site.xml:
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>AKIAlakefs12345EXAMPLE</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>abc/lakefs/1234567bPxRfiCYEXAMPLEKEY</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>https://example-org.us-east-1.lakefscloud.io</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
</configuration>
Use the below configuration when creating the cluster. You may delete any app configuration that is not suitable for your use case:
[
{
"Classification": "spark-defaults",
"Properties": {
"spark.sql.catalogImplementation": "hive"
}
},
{
"Classification": "core-site",
"Properties": {
"fs.s3.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.path.style.access": "true",
"fs.s3a.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.path.style.access": "true"
}
},
{
"Classification": "emrfs-site",
"Properties": {
"fs.s3.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.path.style.access": "true",
"fs.s3a.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.path.style.access": "true"
}
},
{
"Classification": "presto-connector-hive",
"Properties": {
"hive.s3.aws-access-key": "AKIAIOSFODNN7EXAMPLE",
"hive.s3.aws-secret-key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"hive.s3.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"hive.s3.path-style-access": "true",
"hive.s3-file-system-type": "PRESTO"
}
},
{
"Classification": "hive-site",
"Properties": {
"fs.s3.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.path.style.access": "true",
"fs.s3a.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.path.style.access": "true"
}
},
{
"Classification": "hdfs-site",
"Properties": {
"fs.s3.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.path.style.access": "true",
"fs.s3a.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.path.style.access": "true"
}
},
{
"Classification": "mapred-site",
"Properties": {
"fs.s3.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.path.style.access": "true",
"fs.s3a.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.path.style.access": "true"
}
}
]
Alternatively, you can pass these configuration values when adding a step.
For example:
aws emr add-steps --cluster-id j-197B3AEGQ9XE4 \
--steps="Type=Spark,Name=SparkApplication,ActionOnFailure=CONTINUE, \
Args=[--conf,spark.hadoop.fs.s3a.access.key=AKIAIOSFODNN7EXAMPLE, \
--conf,spark.hadoop.fs.s3a.secret.key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY, \
--conf,spark.hadoop.fs.s3a.endpoint=https://example-org.us-east-1.lakefscloud.io, \
--conf,spark.hadoop.fs.s3a.path.style.access=true, \
s3a://<lakefs-repo>/<lakefs-branch>/path/to/jar]"
Per-bucket configuration
The above configuration will use lakeFS as the sole S3 endpoint. To use lakeFS in parallel with S3, you can configure Spark to use lakeFS only for specific bucket names.
For example, to configure only example-repo to use lakeFS, set the following configurations:
spark-shell --conf spark.hadoop.fs.s3a.bucket.example-repo.access.key='AKIAlakefs12345EXAMPLE' \
--conf spark.hadoop.fs.s3a.bucket.example-repo.secret.key='abc/lakefs/1234567bPxRfiCYEXAMPLEKEY' \
--conf spark.hadoop.fs.s3a.bucket.example-repo.endpoint='https://example-org.us-east-1.lakefscloud.io' \
--conf spark.hadoop.fs.s3a.path.style.access=true
spark.sparkContext.hadoopConfiguration.set("fs.s3a.bucket.example-repo.access.key", "AKIAlakefs12345EXAMPLE")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.bucket.example-repo.secret.key", "abc/lakefs/1234567bPxRfiCYEXAMPLEKEY")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.bucket.example-repo.endpoint", "https://example-org.us-east-1.lakefscloud.io")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.path.style.access", "true")
Add these into a configuration file, e.g. $SPARK_HOME/conf/hdfs-site.xml:
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.s3a.bucket.example-repo.access.key</name>
<value>AKIAlakefs12345EXAMPLE</value>
</property>
<property>
<name>fs.s3a.bucket.example-repo.secret.key</name>
<value>abc/lakefs/1234567bPxRfiCYEXAMPLEKEY</value>
</property>
<property>
<name>fs.s3a.bucket.example-repo.endpoint</name>
<value>https://example-org.us-east-1.lakefscloud.io</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
</configuration>
Use the below configuration when creating the cluster. You may delete any app configuration that is not suitable for your use case:
[
{
"Classification": "spark-defaults",
"Properties": {
"spark.sql.catalogImplementation": "hive"
}
},
{
"Classification": "core-site",
"Properties": {
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.bucket.example-repo.path.style.access": "true",
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.bucket.example-repo.path.style.access": "true"
}
},
{
"Classification": "emrfs-site",
"Properties": {
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.bucket.example-repo.path.style.access": "true",
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.bucket.example-repo.path.style.access": "true"
}
},
{
"Classification": "presto-connector-hive",
"Properties": {
"hive.s3.aws-access-key": "AKIAIOSFODNN7EXAMPLE",
"hive.s3.aws-secret-key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"hive.s3.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"hive.s3.path-style-access": "true",
"hive.s3-file-system-type": "PRESTO"
}
},
{
"Classification": "hive-site",
"Properties": {
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.bucket.example-repo.path.style.access": "true",
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.bucket.example-repo.path.style.access": "true"
}
},
{
"Classification": "hdfs-site",
"Properties": {
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.bucket.example-repo.path.style.access": "true",
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.bucket.example-repo.path.style.access": "true"
}
},
{
"Classification": "mapred-site",
"Properties": {
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3.bucket.example-repo.path.style.access": "true",
"fs.s3a.bucket.example-repo.access.key": "AKIAIOSFODNN7EXAMPLE",
"fs.s3a.bucket.example-repo.secret.key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"fs.s3a.bucket.example-repo.endpoint": "https://example-org.us-east-1.lakefscloud.io",
"fs.s3a.bucket.example-repo.path.style.access": "true"
}
}
]
Alternatively, you can pass these configuration values when adding a step.
For example:
aws emr add-steps --cluster-id j-197B3AEGQ9XE4 \
--steps="Type=Spark,Name=SparkApplication,ActionOnFailure=CONTINUE, \
Args=[--conf,spark.hadoop.fs.s3a.bucket.example-repo.access.key=AKIAIOSFODNN7EXAMPLE, \
--conf,spark.hadoop.fs.s3a.bucket.example-repo.secret.key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY, \
--conf,spark.hadoop.fs.s3a.bucket.example-repo.endpoint=https://example-org.us-east-1.lakefscloud.io, \
--conf,spark.hadoop.fs.s3a.path.style.access=true, \
s3a://<lakefs-repo>/<lakefs-branch>/path/to/jar]"
With this configuration set, you read S3A paths with example-repo as the bucket will use lakeFS, while all other buckets will use AWS S3.
Usage
Here’s an example for reading a Parquet file from lakeFS to a Spark DataFrame:
val repo = "example-repo"
val branch = "main"
val df = spark.read.parquet(s"s3a://${repo}/${branch}/example-path/example-file.parquet")
Here’s how to write some results back to a lakeFS path:
df.write.partitionBy("example-column").parquet(s"s3a://${repo}/${branch}/output-path/")
The data is now created in lakeFS as new changes in your branch. You can now commit these changes or revert them.
Configuring Azure Databricks with the S3-compatible API
If you use Azure Databricks, you can take advantage of the lakeFS S3-compatible API with your Azure account and the S3A FileSystem.
This will require installing the hadoop-aws package (with the same version as your hadoop-azure package) to your Databricks cluster.
Define your FileSystem configurations in the following way:
spark.hadoop.fs.lakefs.impl=org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.lakefs.access.key=‘AKIAlakefs12345EXAMPLE’ // The access key to your lakeFS server
spark.hadoop.fs.lakefs.secret.key=‘abc/lakefs/1234567bPxRfiCYEXAMPLEKEY’ // The secret key to your lakeFS server
spark.hadoop.fs.lakefs.path.style.access=true
spark.hadoop.fs.lakefs.endpoint=‘https://example-org.us-east-1.lakefscloud.io’ // The endpoint of your lakeFS server
For more details about Mounting cloud object storage on Databricks.
Configuring Databricks SQL Warehouse with the S3-compatible API
A SQL warehouse is a compute resource that lets you run SQL commands on data objects within Databricks SQL.
If you use Databricks SQL warehouse, you can take advantage of the lakeFS S3-compatible API with the S3A FileSystem.
Define your SQL Warehouse configurations in the following way:
-
In the top right, select
Admin Settingsand thenCompute, andSQL warehouses. -
Under
Data Access Propertiesadd the following key-value pairs for each lakeFS repository you want to access:
spark.hadoop.fs.s3a.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.bucket.example-repo.access.key AKIAIOSFODNN7EXAMPLE // The access key to your lakeFS server
spark.hadoop.fs.s3a.bucket.example-repo.secret.key wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY // The secret key to your lakeFS server
spark.hadoop.fs.s3a.bucket.example-repo.endpoint https://example-org.us-east-1.lakefscloud.io // The endpoint of your lakeFS server
spark.hadoop.fs.s3a.bucket.example-repo.path.style.access true
- Changes are applied automatically after the SQL Warehouse restarts.
- You can now use the lakeFS S3-compatible API with your SQL Warehouse, e.g.:
SELECT * FROM delta.`s3a://example-repo/main/datasets/delta-table/` LIMIT 100
⚠️ Experimental: Pre-signed mode for S3A
In Hadoop 3.1.4 version and above (as tested using our lakeFS Hadoop FS), it is possible to use pre-signed URLs as return values from the lakeFS S3 Gateway.
This has the immediate benefit of reducing the amount of traffic that has to go through the lakeFS server thus improving IO performance. To read more about pre-signed URLs, see this guide.
Here’s an example Spark configuration to enable this support:
spark.hadoop.fs.s3a.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.bucket.example-repo.access.key AKIAIOSFODNN7EXAMPLE // The access key to your lakeFS server
spark.hadoop.fs.s3a.bucket.example-repo.secret.key wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY // The secret key to your lakeFS server
spark.hadoop.fs.s3a.path.style.access true
spark.hadoop.fs.s3a.bucket.example-repo.signing-algorithm QueryStringSignerType
spark.hadoop.fs.s3a.bucket.example-repo.user.agent.prefix s3RedirectionSupport
user.agent.prefix should contain the string s3RedirectionSupport but does not have to match the string exactly.
Once configured, requests will include the string s3RedirectionSupport in the User-Agent HTTP header sent with GetObject requests, resulting in lakeFS responding with a pre-signed URL.
Setting the signing-algorithm to QueryStringSignerType is required to stop S3A from signing a pre-signed URL, since the existence of more than one signature method will return an error from S3.
ℹ This feature requires a lakeFS server of version >1.18.0
lakeFS Hadoop FileSystem
If you’re using lakeFS on top of S3, this mode will enhance your application’s performance. In this mode, Spark will read and write objects directly from S3, reducing the load on the lakeFS server. It will still access the lakeFS server for metadata operations.
After configuring the lakeFS Hadoop FileSystem below, use URIs of the form lakefs://example-repo/ref/path/to/data to
interact with your data on lakeFS.
Installation
Add the package to your spark-submit command:
--packages io.lakefs:hadoop-lakefs-assembly:0.2.5
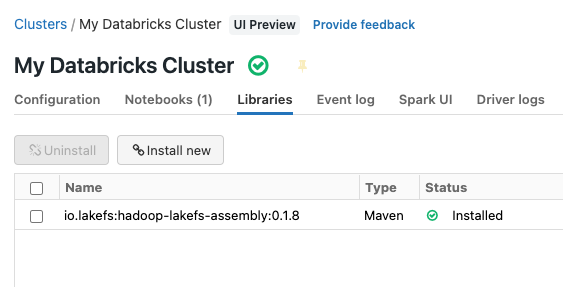
In your cluster settings, under the Libraries tab, add the following Maven package:
io.lakefs:hadoop-lakefs-assembly:0.2.5
Once installed, it should look something like this:
Add the package to your pyspark or spark-submit command:
--packages io.lakefs:hadoop-lakefs-assembly:0.2.5
Add the configuration to access the S3 bucket used by lakeFS to your pyspark or spark-submit command or add this configuration at the Cloudera cluster level (see below):
--conf spark.yarn.access.hadoopFileSystems=s3a://bucket-name
Add the configuration to access the S3 bucket used by lakeFS at the Cloudera cluster level:
- Log in to the CDP (Cloudera Data Platform) web interface.
- From the CDP home screen, click the
Management Consoleicon. - In the Management Console, select
Data Hub Clustersfrom the navigation pane. - Select the cluster you want to configure. Click on
CM-UIlink under Services: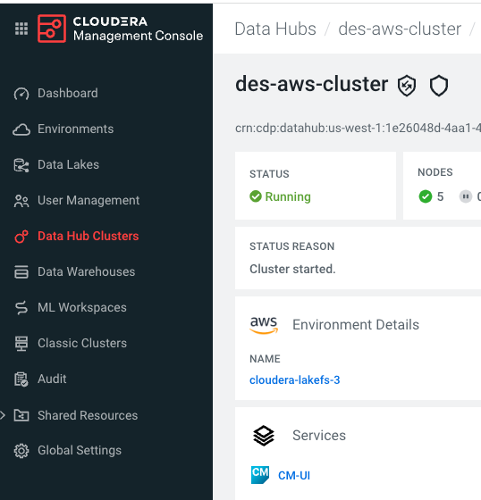
- In Cloudera Manager web interface, click on
Clustersfrom the navigation pane and click onspark_on_yarnoption: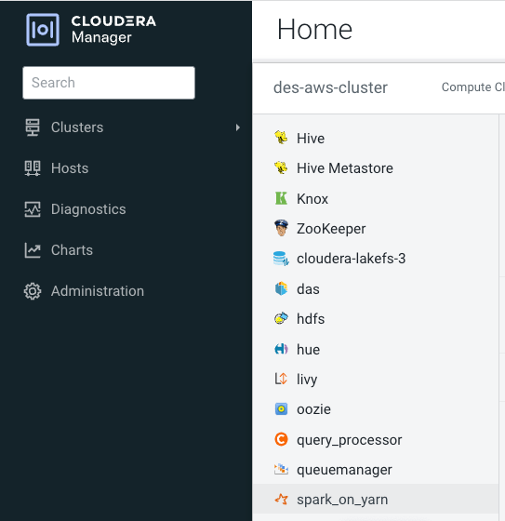
- Click on
Configurationtab and search forspark.yarn.access.hadoopFileSystemsin the search box: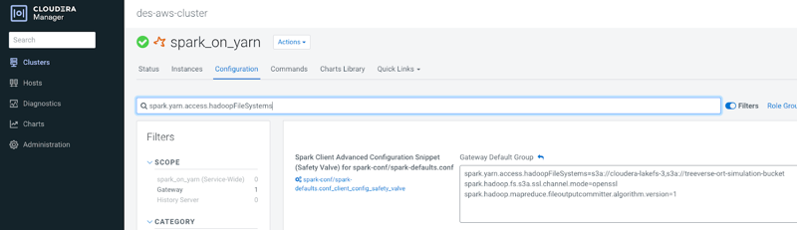
- Add S3 bucket used by lakeFS
s3a://bucket-namein thespark.yarn.access.hadoopFileSystemslist: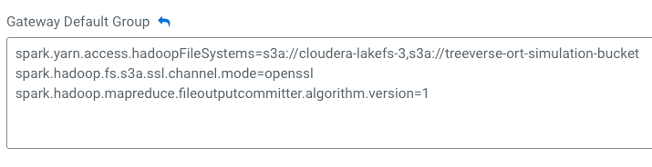
Configuration
Set the fs.lakefs.* Hadoop configurations to point to your lakeFS installation:
fs.lakefs.impl:io.lakefs.LakeFSFileSystemfs.lakefs.access.key: lakeFS access keyfs.lakefs.secret.key: lakeFS secret keyfs.lakefs.endpoint: lakeFS API URL (e.g.https://example-org.us-east-1.lakefscloud.io/api/v1)
Configure the lakeFS client to use a temporary token instead of static credentials:
fs.lakefs.auth.provider: The default isbasic_authwithfs.lakefs.access.keyandfs.lakefs.secret.keyfor basic authentication. Can be set toio.lakefs.auth.TemporaryAWSCredentialsLakeFSTokenProviderfor using temporary AWS credentials, you can read more about it here.
When using io.lakefs.auth.TemporaryAWSCredentialsLakeFSTokenProvider as the auth provider the following configuration are relevant:
fs.lakefs.token.aws.access.key: AWS assumed role access keyfs.lakefs.token.aws.secret.key: AWS assumed role secret keyfs.lakefs.token.aws.session.token: AWS assumed role temporary session tokenfs.lakefs.token.aws.sts.endpoint: AWS STS regional endpoint for generated the presigned-url (i.ehttps://sts.us-west-2.amazonaws.com)fs.lakefs.token.aws.sts.duration_seconds: Optional, the duration in seconds for the initial identity token (default is 60)fs.lakefs.token.duration_seconds: Optional, the duration in seconds for the lakeFS token (default is set in the lakeFS configuration auth.login_duration)fs.lakefs.token.sts.additional_headers: Optional, comma separated list ofheader:valueto attach when generating presigned sts request. Default isX-Lakefs-Server-ID:fs.lakefs.endpoint.
Configure the S3A FileSystem to access your S3 storage, for example using the fs.s3a.* configurations (these are not your lakeFS credentials):
fs.s3a.access.key: AWS S3 access keyfs.s3a.secret.key: AWS S3 secret key
Here are some configuration examples:
spark-shell --conf spark.hadoop.fs.s3a.access.key='AKIAIOSFODNN7EXAMPLE' \
--conf spark.hadoop.fs.s3a.secret.key='wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' \
--conf spark.hadoop.fs.s3a.endpoint='https://s3.eu-central-1.amazonaws.com' \
--conf spark.hadoop.fs.lakefs.impl=io.lakefs.LakeFSFileSystem \
--conf spark.hadoop.fs.lakefs.access.key=AKIAlakefs12345EXAMPLE \
--conf spark.hadoop.fs.lakefs.secret.key=abc/lakefs/1234567bPxRfiCYEXAMPLEKEY \
--conf spark.hadoop.fs.lakefs.endpoint=https://example-org.us-east-1.lakefscloud.io/api/v1 \
--packages io.lakefs:hadoop-lakefs-assembly:0.2.5 \
io.example.ExampleClass
spark.sparkContext.hadoopConfiguration.set("fs.s3a.access.key", "AKIAIOSFODNN7EXAMPLE")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.secret.key", "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.endpoint", "https://s3.eu-central-1.amazonaws.com")
spark.sparkContext.hadoopConfiguration.set("fs.lakefs.impl", "io.lakefs.LakeFSFileSystem")
spark.sparkContext.hadoopConfiguration.set("fs.lakefs.access.key", "AKIAlakefs12345EXAMPLE")
spark.sparkContext.hadoopConfiguration.set("fs.lakefs.secret.key", "abc/lakefs/1234567bPxRfiCYEXAMPLEKEY")
spark.sparkContext.hadoopConfiguration.set("fs.lakefs.endpoint", "https://example-org.us-east-1.lakefscloud.io/api/v1")
sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", "AKIAIOSFODNN7EXAMPLE")
sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY")
sc._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "https://s3.eu-central-1.amazonaws.com")
sc._jsc.hadoopConfiguration().set("fs.lakefs.impl", "io.lakefs.LakeFSFileSystem")
sc._jsc.hadoopConfiguration().set("fs.lakefs.access.key", "AKIAlakefs12345EXAMPLE")
sc._jsc.hadoopConfiguration().set("fs.lakefs.secret.key", "abc/lakefs/1234567bPxRfiCYEXAMPLEKEY")
sc._jsc.hadoopConfiguration().set("fs.lakefs.endpoint", "https://example-org.us-east-1.lakefscloud.io/api/v1")
Make sure that you load the lakeFS FileSystem into Spark by running it with --packages or --jars,
and then add these into a configuration file, e.g., $SPARK_HOME/conf/hdfs-site.xml:
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>AKIAIOSFODNN7EXAMPLE</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>https://s3.eu-central-1.amazonaws.com</value>
</property>
<property>
<name>fs.lakefs.impl</name>
<value>io.lakefs.LakeFSFileSystem</value>
</property>
<property>
<name>fs.lakefs.access.key</name>
<value>AKIAlakefs12345EXAMPLE</value>
</property>
<property>
<name>fs.lakefs.secret.key</name>
<value>abc/lakefs/1234567bPxRfiCYEXAMPLEKEY</value>
</property>
<property>
<name>fs.lakefs.endpoint</name>
<value>https://example-org.us-east-1.lakefscloud.io/api/v1</value>
</property>
</configuration>
Add the following the cluster’s configuration under Configuration ➡️ Advanced options:
spark.hadoop.fs.lakefs.impl io.lakefs.LakeFSFileSystem
spark.hadoop.fs.lakefs.access.key AKIAlakefs12345EXAMPLE
spark.hadoop.fs.lakefs.secret.key abc/lakefs/1234567bPxRfiCYEXAMPLEKEY
spark.hadoop.fs.s3a.access.key AKIAIOSFODNN7EXAMPLE
spark.hadoop.fs.s3a.secret.key wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
spark.hadoop.fs.s3a.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.lakefs.endpoint https://example-org.us-east-1.lakefscloud.io/api/v1
Alternatively, follow this step by step Databricks integration tutorial, including lakeFS Hadoop File System, Python client and lakeFS SPARK client.
⚠️ If your bucket is on a region other than us-east-1, you may also need to configure fs.s3a.endpoint with the correct region.
Amazon provides S3 endpoints you can use.
Usage with TemporaryAWSCredentialsLakeFSTokenProvider
An initial setup is required - you must have AWS Auth configured with lakeFS.
The TemporaryAWSCredentialsLakeFSTokenProvider depends on the caller to provide AWS credentials (e.g Assumed Role Key,Secret and Token) as input to the lakeFS client.
⚠️ Configure sts.endpoint with a valid sts regional service endpoint and it must be be equal to the region that is used for authentication first place. The only exception is us-east-1 which is the default region for STS.
⚠️ Using the current provider the lakeFS token will not renew upon expiry and the user will need to re-authenticate.
PySpark example using TemporaryAWSCredentialsLakeFSTokenProvider with boto3 and AWS session credentials:
import boto3
session = boto3.session.Session()
# AWS credentials used s3a to access lakeFS bucket
sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", "AKIAIOSFODNN7EXAMPLE")
sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY")
sc._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "https://s3.us-west-2.amazonaws.com")
sc._jsc.hadoopConfiguration().set("fs.lakefs.impl", "io.lakefs.LakeFSFileSystem")
sc._jsc.hadoopConfiguration().set("fs.lakefs.endpoint", "https://example-org.us-west-2.lakefscloud.io/api/v1")
sc._jsc.hadoopConfiguration().set("spark.hadoop.fs.s3a.path.style.access", "true")
sc._jsc.hadoopConfiguration().set("fs.lakefs.auth.provider", "io.lakefs.auth.TemporaryAWSCredentialsLakeFSTokenProvider")
# AWS tempporary session credentials to use with lakeFS
sc._jsc.hadoopConfiguration().set("fs.lakefs.token.aws.access.key", session.get_credentials().access_key)
sc._jsc.hadoopConfiguration().set("fs.lakefs.token.aws.secret.key", session.get_credentials().secret_key)
sc._jsc.hadoopConfiguration().set("fs.lakefs.token.aws.session.token", session.get_credentials().token)
sc._jsc.hadoopConfiguration().set("fs.lakefs.token.aws.sts.endpoint", "https://sts.us-west-2.amazonaws.com")
Usage
Hadoop FileSystem paths use the lakefs:// protocol, with paths taking the form lakefs://<repository>/<ref>/path/to/object.
<ref> can be a branch, tag, or commit ID in lakeFS.
Here’s an example for reading a Parquet file from lakeFS to a Spark DataFrame:
val repo = "example-repo"
val branch = "main"
val df = spark.read.parquet(s"lakefs://${repo}/${branch}/example-path/example-file.parquet")
Here’s how to write some results back to a lakeFS path:
df.write.partitionBy("example-column").parquet(s"lakefs://${repo}/${branch}/output-path/")
The data is now created in lakeFS as new changes in your branch. You can now commit these changes or revert them.
Hadoop FileSystem in Presigned mode
Available starting version 0.1.13 of the FileSystem
In this mode, the lakeFS server is responsible for authenticating with your storage. The client will still perform data operations directly on the storage. To do so, it will use pre-signed storage URLs provided by the lakeFS server.
When using this mode, you don’t need to configure the client with access to your storage:
spark-shell --conf spark.hadoop.fs.lakefs.access.mode=presigned \
--conf spark.hadoop.fs.lakefs.impl=io.lakefs.LakeFSFileSystem \
--conf spark.hadoop.fs.lakefs.access.key=AKIAlakefs12345EXAMPLE \
--conf spark.hadoop.fs.lakefs.secret.key=abc/lakefs/1234567bPxRfiCYEXAMPLEKEY \
--conf spark.hadoop.fs.lakefs.endpoint=https://example-org.us-east-1.lakefscloud.io/api/v1 \
--packages io.lakefs:hadoop-lakefs-assembly:0.2.5
spark.sparkContext.hadoopConfiguration.set("fs.lakefs.access.mode", "presigned")
spark.sparkContext.hadoopConfiguration.set("fs.lakefs.impl", "io.lakefs.LakeFSFileSystem")
spark.sparkContext.hadoopConfiguration.set("fs.lakefs.access.key", "AKIAlakefs12345EXAMPLE")
spark.sparkContext.hadoopConfiguration.set("fs.lakefs.secret.key", "abc/lakefs/1234567bPxRfiCYEXAMPLEKEY")
spark.sparkContext.hadoopConfiguration.set("fs.lakefs.endpoint", "https://example-org.us-east-1.lakefscloud.io/api/v1")
sc._jsc.hadoopConfiguration().set("fs.lakefs.access.mode", "presigned")
sc._jsc.hadoopConfiguration().set("fs.lakefs.impl", "io.lakefs.LakeFSFileSystem")
sc._jsc.hadoopConfiguration().set("fs.lakefs.access.key", "AKIAlakefs12345EXAMPLE")
sc._jsc.hadoopConfiguration().set("fs.lakefs.secret.key", "abc/lakefs/1234567bPxRfiCYEXAMPLEKEY")
sc._jsc.hadoopConfiguration().set("fs.lakefs.endpoint", "https://example-org.us-east-1.lakefscloud.io/api/v1")
Make sure that you load the lakeFS FileSystem into Spark by running it with --packages or --jars,
and then add these into a configuration file, e.g., $SPARK_HOME/conf/hdfs-site.xml:
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.lakefs.access.mode</name>
<value>presigned</value>
</property>
<property>
<name>fs.lakefs.impl</name>
<value>io.lakefs.LakeFSFileSystem</value>
</property>
<property>
<name>fs.lakefs.access.key</name>
<value>AKIAlakefs12345EXAMPLE</value>
</property>
<property>
<name>fs.lakefs.secret.key</name>
<value>abc/lakefs/1234567bPxRfiCYEXAMPLEKEY</value>
</property>
<property>
<name>fs.lakefs.endpoint</name>
<value>https://example-org.us-east-1.lakefscloud.io/api/v1</value>
</property>
</configuration>
Add the following the cluster’s configuration under Configuration ➡️ Advanced options:
spark.hadoop.fs.lakefs.access.mode presigned
spark.hadoop.fs.lakefs.impl io.lakefs.LakeFSFileSystem
spark.hadoop.fs.lakefs.access.key AKIAlakefs12345EXAMPLE
spark.hadoop.fs.lakefs.secret.key abc/lakefs/1234567bPxRfiCYEXAMPLEKEY
spark.hadoop.fs.lakefs.endpoint https://example-org.us-east-1.lakefscloud.io/api/v1