
Using MLflow with lakeFS
MLflow is a comprehensive tool designed to manage the machine learning lifecycle, assisting practitioners and teams in handling the complexities of ML processes. It focuses on the full lifecycle of machine learning projects, ensuring that each phase is manageable, traceable, and reproducible.
MLflow comprises multiple core components, and lakeFS seamlessly integrates with the MLflow Tracking component. MLflow tracking enables experiment tracking that accounts for both inputs and outputs, allowing for visualization and comparison of experiment results.
Benefits of integrating MLflow with lakeFS
Integrating MLflow with lakeFS offers several advantages that enhance the machine learning workflow:
- Experiment Reproducibility: By leveraging MLflow’s input logging capabilities alongside lakeFS’s data versioning, you can precisely track the specific dataset version used in each experiment run. This ensures that experiments remain reproducible over time, even as datasets evolve.
- Parallel Experiments with Zero Data Copy: Parallel Experiments with Zero Data Copy: lakeFS enables efficient branching without duplicating data. This allows for multiple experiments to be conducted in parallel, with each branch providing an isolated environment for dataset modifications. Changes in one branch do not affect others, promoting safe collaboration among team members. Once an experiment is complete, the branch can be seamlessly merged back into the main dataset, incorporating new insights.
How to use MLflow with lakeFS
To harness the combined capabilities of MLflow and lakeFS for safe experimentation and accurate result reproduction, consider the workflow below and review the practical examples provided on the next section.
Recommended workflow
- Create a branch for each experiment: Start each experiment by creating a dedicated lakeFS branch for it. This approach allows you to safely make changes to your input dataset without duplicating it. You will later load data from this branch to your MLflow experiment runs.
- Read datasets from the experiment branch: Read Datasets from the Experiment Branch: Conduct your experiments by reading data directly from the dedicated branch. We recommend to read the dataset from the head commit of the branch to ensure precise version tracking.
- Create an MLflow Dataset pointing to lakeFS: Use MLflow’s Dataset ensuring that the dataset source points to lakeFS.
- Log your input: Use MLflow’s log_input function to log the versioned dataset stored in lakeFS.
- Commit dataset changes: Machine learning development is inherently iterative. When you make changes to your input dataset, commit them to the experiment branch in lakeFS with a meaningful commit message. During an experiment run, load the dataset version corresponding to the branch’s head commit and track this reference to facilitate future result reproduction.
- Merge experiment results: After concluding your experimentation, merge the branch used for the selected experiment run back into the main branch.
Note: Branch per experiment Vs. Branch per experiment run
While it’s possible to create a lakeFS branch for each experiment run, given that lakeFS branches are both quick and
cost-effective to create, it’s often more efficient to create a branch per experiment. By reading directly from the head
commit of the experiment branch, you can distinguish between dataset versions without creating excessive branches. This
practice maintains branch hygiene within lakeFS.
Example: Using Pandas
import lakefs
import mlflow
import pandas as pd
repo = lakefs.Repository("my-repo")
repo_id = repo.id
exp_branch = repo.branch("experiment-1").create(source_reference="main", exist_ok=True)
branch_id = exp_branch.id
head_commit_id = exp_branch.head.id
table_path = "famous_people.csv"
dataset_source_url = f"s3://{repo_id}/{head_commit_id}/{table_path}"
# Use Pandas to read from lakeFS, at its most updated version to which the head commit id is pointing
raw_data = pd.read_csv(dataset_source_url, delimiter=";", storage_options={
"key": "AKIAIOSFOLKFSSAMPLES",
"secret": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"client_kwargs": {"endpoint_url": "http://localhost:8000"}
})
# Create an instance of a PandasDataset
dataset = mlflow.data.from_pandas(
raw_data, source=dataset_source_url, name="famous_people"
)
# View some of the recorded Dataset information
print(f"Dataset name: {dataset.name}")
print(f"Dataset source URI: {dataset.source.uri}")
# Use mlflow input logging to track the dataset versioned by lakeFS
with mlflow.start_run() as run:
mlflow.log_input(dataset, context="training")
mlflow.set_tag("lakefs_repo", repo_id)
mlflow.set_tag("lakefs_branch", branch_id)
# Inspect run's dataset
logged_run = mlflow.get_run(run.info.run_id) #
# Retrieve the Dataset object
logged_dataset = logged_run.inputs.dataset_inputs[0].dataset
# View some of the recorded Dataset information
print(f"Logged dataset name: {logged_dataset.name}")
print(f"Logged dataset source URI: {logged_dataset.source}")
Output
Dataset name: famous_people
Dataset source URI: s3://my-repo/3afddad4fef987b4919f5e82f16682c018f59ed2ff003a6a81adf72edaad23c3/fp.csv
Logged dataset name: famous_people
Logged dataset source URI: {"uri": "s3://my-repo/3afddad4fef987b4919f5e82f16682c018f59ed2ff003a6a81adf72edaad23c3/fp.csv"}
Example: Using Spark
The example below configures Spark to access lakeFS’ S3-compatible API and load a Delta Lake tables to the experiment.
import lakefs
import mlflow
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("lakeFS / Mlflow") \
.config("spark.hadoop.fs.s3.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \
.config("spark.hadoop.fs.s3a.endpoint", 'http://localhost:8000') \
.config("spark.hadoop.fs.s3a.path.style.access", "true") \
.config("spark.hadoop.fs.s3a.access.key", 'AKIAlakefs12345EXAMPLE') \
.config("spark.hadoop.fs.s3a.secret.key", 'abc/lakefs/1234567bPxRfiCYEXAMPLEKEY') \
.config("spark.jars.packages", "io.delta:delta-core_2.12:2.3.0") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
repo = lakefs.Repository("my-repo")
repo_id = repo.id
exp_branch = repo.branch("experiment-1").create(source_reference="main", exist_ok=True)
branch_id = exp_branch.id
head_commit_id = exp_branch.head.id
table_path = "gold/train_v2/"
dataset_source_url = f"s3://{repo_id}/{head_commit_id}/{table_path}"
# Load delta lake table from lakeFS, at its most updated version to which the head commit id is pointing
dataset = mlflow.data.load_delta(path=dataset_source_url, name="boat-images")
# View some of the recorded Dataset information
print(f"Dataset name: {dataset.name}")
print(f"Dataset source URI: {dataset.source.path}")
# Use mlflow input logging to track the dataset versioned by lakeFS
with mlflow.start_run() as run:
mlflow.log_input(dataset, context="training")
mlflow.set_tag("lakefs_repo", repo_id)
mlflow.set_tag("lakefs_branch", branch_id) # Log the branch id, to have a friendly lakeFS reference to search the input dataset in
# Inspect run's dataset
logged_run = mlflow.get_run(run.info.run_id) #
# Retrieve the Dataset object
logged_dataset = logged_run.inputs.dataset_inputs[0].dataset
# View some of the recorded Dataset information
print(f"Logged dataset name: {logged_dataset.name}")
print(f"Logged dataset source URI: {logged_dataset.source}")
Output
Dataset name: boat-images
Dataset source URI: s3://my-repo/3afddad4fef987b4919f5e82f16682c018f59ed2ff003a6a81adf72edaad23c3/gold/train_v2/
Logged dataset name: boat-images
Logged dataset source URI: {"path": "s3://my-repo/3afddad4fef987b4919f5e82f16682c018f59ed2ff003a6a81adf72edaad23c3/gold/train_v2/"}
Reproduce experiment results
To reproduce the results of a specific experiment run in MLflow, it’s essential to retrieve the exact dataset and associated metadata used during that run. While the MLflow Tracking UI provides a general overview, detailed dataset information and its source are best accessed programmatically.
- Obtain the Run ID: Navigate to the MLflow UI and copy the Run ID of the experiment you’re interested in.
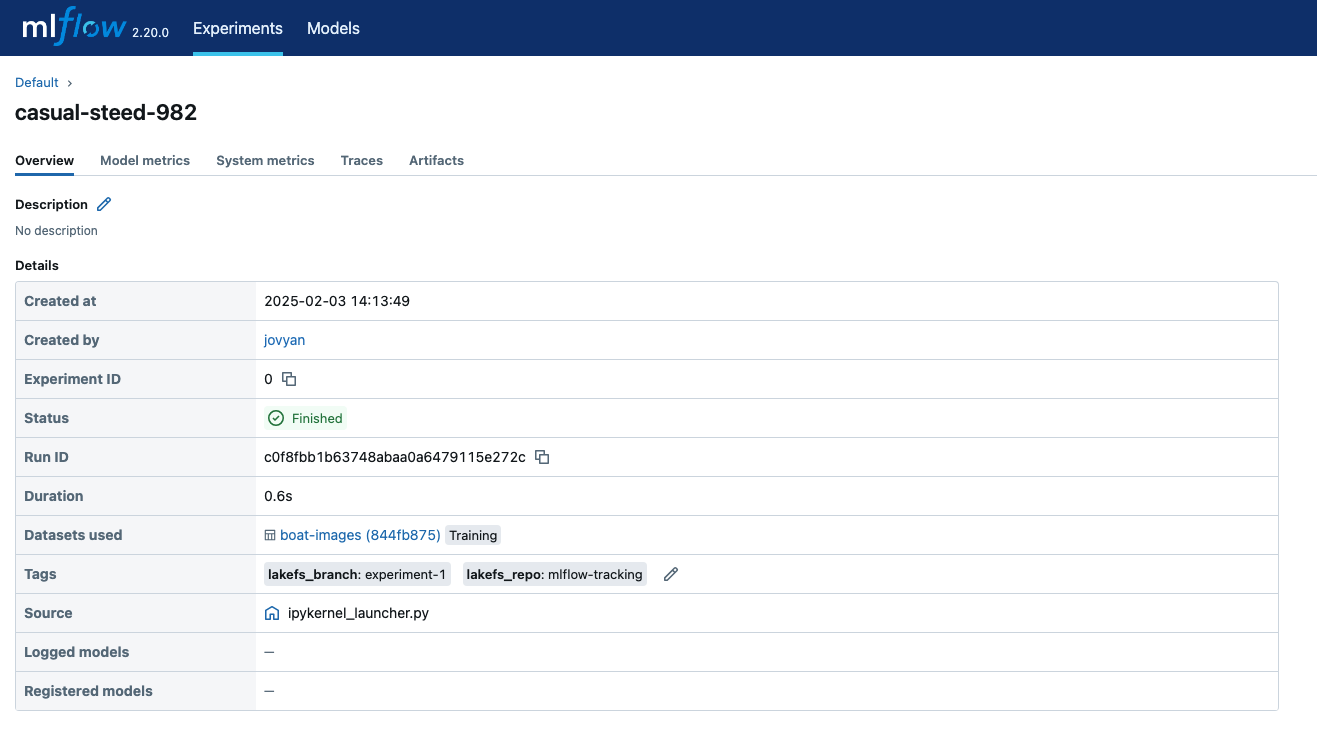
- Extract Dataset Information Using MLflow’s Python SDK:
import mlflow
# Inspect run's dataset and tags
run_id = "c0f8fbb1b63748abaa0a6479115e272c"
run = mlflow.get_run(run_id)
# Retrieve the Dataset object
logged_dataset = run.inputs.dataset_inputs[0].dataset
# View some of the recorded Dataset information
print(f"Run ID: {run_id} Dataset name: {logged_dataset.name}")
print(f"Run ID: {run_id} Dataset source URI: {logged_dataset.source}")
# Retrieve run's tags
logged_tags = run.data.tags
print(f"Run ID: {run_id} tags: {logged_tags}")
Output
Run ID: c0f8fbb1b63748abaa0a6479115e272c Dataset name: boat-images
Run ID: c0f8fbb1b63748abaa0a6479115e272c Dataset source URI: {"path": "s3://my-repo/3afddad4fef987b4919f5e82f16682c018f59ed2ff003a6a81adf72edaad23c3/gold/train_v2/"}
Run ID: c0f8fbb1b63748abaa0a6479115e272c tags: {'lakefs_branch': 'experiment-1', 'lakefs_repo': 'my-repo'}
Notes:
- The Dataset Source URI provides the location of the dataset at the exact version used in the run.
- Run tags, such as ‘lakefs_branch’ and ‘lakefs_repo’, offer additional context about the dataset’s origin within lakeFS.
Compare runs input
To determine whether two distinct MLflow runs utilized the same input dataset, you can compare specific attributes of their logged Dataset objects. The source attribute, which contains the versioned dataset’s URI, is a common choice for this comparison. Here’s an example:
import mlflow
first_run_id = "4c0464d665944dc5bb90587d455948b8"
first_run = mlflow.get_run(first_run_id)
# Retrieve the Dataset object
first_dataset = first_run.inputs.dataset_inputs[0].dataset
first_dataset_src = first_dataset.source
sec_run_id = "12b91e073a8b40df97ea8d570534de31"
sec_run = mlflow.get_run(sec_run_id)
# Retrieve the Dataset object
sec_dataset = sec_run.inputs.dataset_inputs[0].dataset
sec_dataset_src = sec_dataset.source
assert first_dataset_src == sec_dataset_src, "Dataset sources are not equal."
print(f"First dataset src: {first_dataset_src}")
print(f"Second dataset src: {sec_dataset_src}")
Output
First dataset src: {"uri": "s3://mlflow-tracking/f16682c0186a81adf72edaad23c3f59ed2ff3afddad4fef987b4919f5e82003a/gold/train_v2/"}
Second dataset src: {"uri": "s3://mlflow-tracking/3afddad4fef987b4919f5e82f16682c018f59ed2ff003a6a81adf72edaad23c3/gold/train_v2/"}
In this example, the source attribute of each Dataset object is compared to determine if the input datasets are identical. If they differ, you can further inspect them. With the dataset source URI in hand, you can use lakeFS to gain more insights about the changes made to your dataset:
- Inspect the lakeFS Commit ID: By examining the commit ID within the URI, you can retrieve detailed information about the commit, including the author and the purpose of the changes.
- Use lakeFS Diff: lakeFS offers a diff function that allows you to compare different versions of your data.
By leveraging these tools, you can effectively track and understand the evolution of your datasets across different MLflow runs.